The testing trade-off triangle

This article is part of a series on “Testing Serverless Applications” based on lessons I teach in the Serverless Testing Workshop.
Writing automated tests for serverless applications, indeed for any type of software application, can be somewhat of an art. Answers to the following commonly asked questions will be highly contextual and unique to an individual project or even a component/use case within a project:
- How many tests should I write?
- What type of tests (unit, integration, E2E) should I write?
- How can I make these tests run faster?
- Can/should I run these tests on my local machine?
- What test coverage do we need? And how do I measure it?
I have observed a few different schools of thought on the best way to approach testing serverless applications amongst respected practitioners. These schools of thought are roughly split across two dimensions:
- Local vs cloud-based testing
- The weights given to each test granularity (unit, integration and end-to-end) within your test portfolio (e.g. the traditional test pyramid vs the microservices test honeycomb)
I have some thoughts on these based on my own experiences but I’ll save those for another article.
Get back to the basics of testing
What I do find useful to help answer the above questions for a specific context is to go up a level and first remind myself of why we write automated tests in the first place.
The first and foremost objective is confidence.
The tests should give sufficient confidence to the relevant stakeholders (engineers, product managers, business folks, end users) that the system is behaving as expected. This allows for decisions (automated or otherwise) to be made about the releasability of the system (or subcomponents of it). To do this well, the engineer authoring the tests needs a good knowledge of both the functional requirements and the deployment landscape (e.g. the AWS cloud services) and its failure modes.
Following on from this core objective of confidence, I see two further objectives for an automated test suite:
- Feedback loop: the faster we learn about a failure and are able to identify its root cause, the faster a fix can be put in place. This feedback loop is relevant both in the context of a developer’s iterative feature dev process inside their own individual environment and also within shared environments (test, staging, prod) as part of a CI/CD pipeline. Both the speed and quality of the feedback related to a test failure are important here.
- Maintainability: How long does it take to write the tests in the first place? Are our tests making the system easier or more difficult to maintain in the long term? Do they require a lot of hand-holding/patching due to transient issues? Do the tests help new developers understand the system better or do they just add to their overwhelm?
The tension between each objective
So we’ve reflected on the three high-level objectives for why we write tests in the first place. These objectives aren’t boolean but are instead on a sliding scale—a test needs to have “enough” of each level to be of net positive value and therefore be worth keeping (or writing in the first place).
Secondly, and crucially, each objective is often in conflict with at least one of the other two.
This is what I call the testing trade-off triangle.
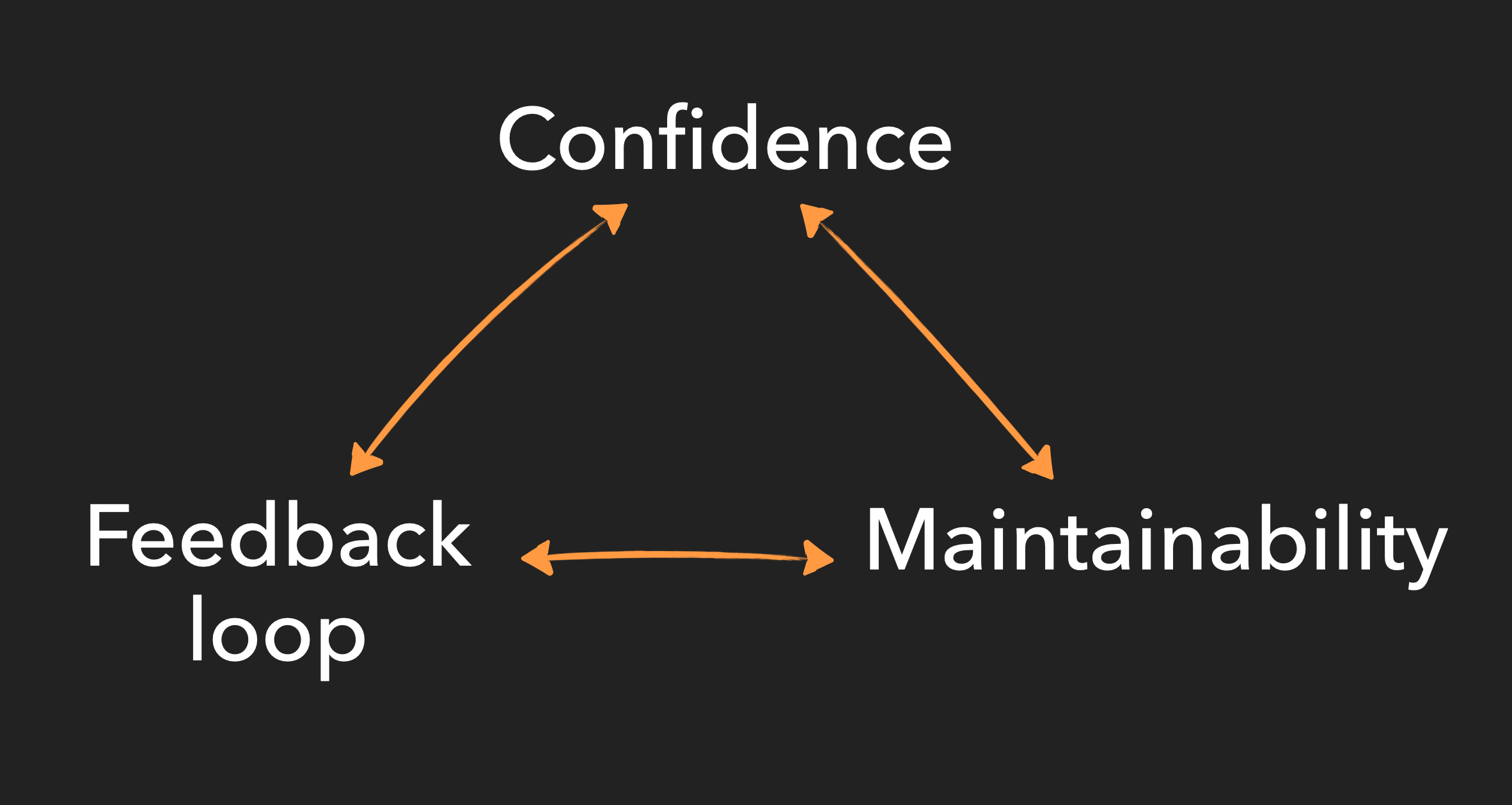
The general principle is that when deciding upon your testing approach for a new system (or a new feature/change to an existing system), you need to make a compromise between confidence level, feedback loop and maintainability.
I believe this trade-off holds true for all categories of software development projects, not just serverless systems.
Example 1: Optimise for maximum confidence
Say that for every system use case, you write an exhaustive suite of tests covering every eventuality, both functional and environmental.

By doing this you’re stealing from the maintainability pot as the time taken to write all these tests will mean you can’t meet any deadlines that most businesses inevitably have.
Example 2: Optimise solely for fast feedback
Take another example where you optimise for the feedback loop objective by writing all your tests as lightning fast, in-memory unit tests, swapping out integrations with cloud services with a form of test double.
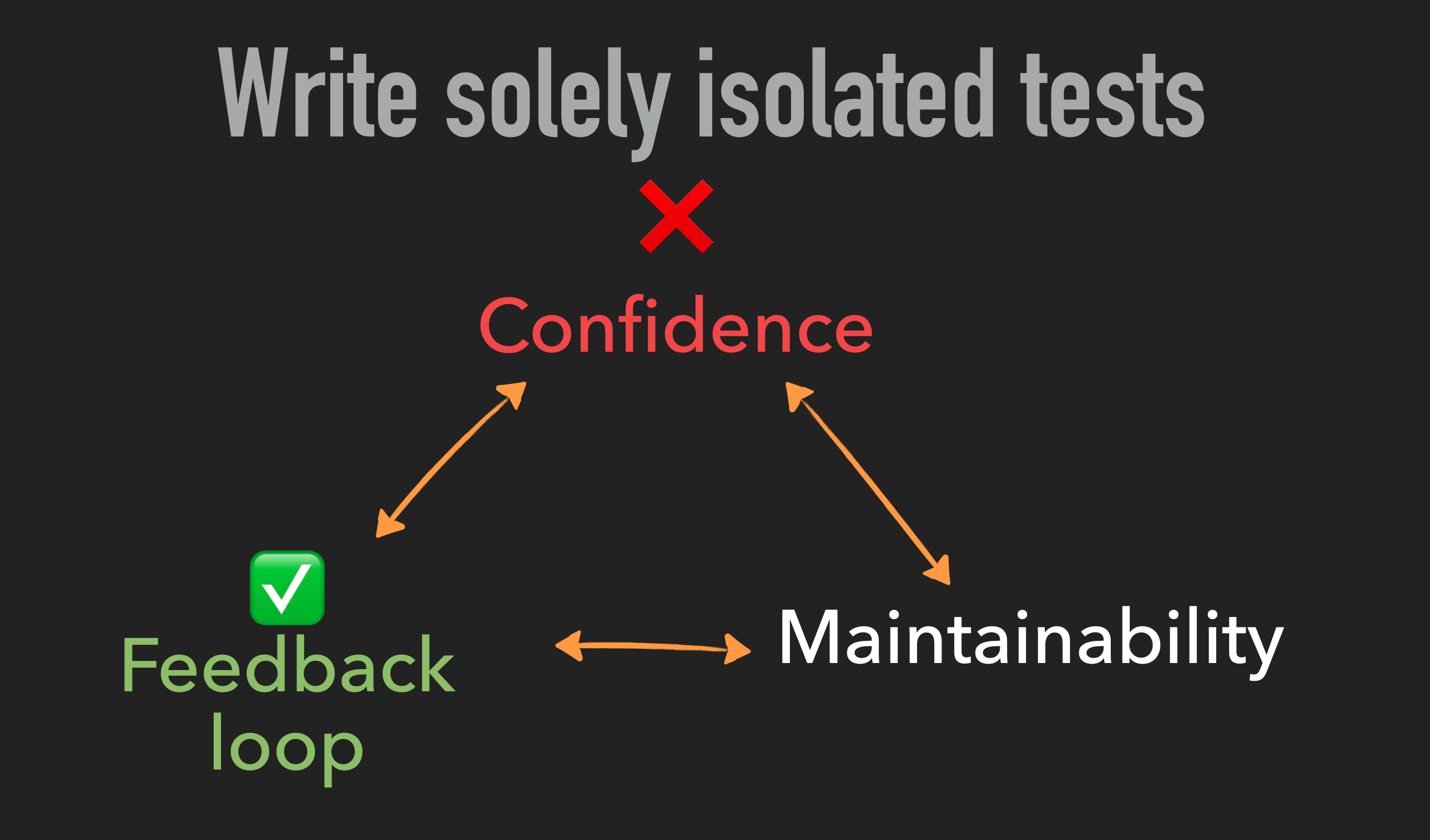
The loser here is the confidence objective. While we gain confidence that each individual component works as intended (and can iterate really quickly locally without making cloud round-trips), we don’t get any confidence that the components will work together when deployed to a full environment (you’ve seen the memes!). And in serverless applications—where these components and their associated integration points are more numerous than ever—this is even more problematic.
(You could also make a case that the maintainability aspect would suffer in this example, since identifying, injecting and maintaining a suitable test double can take time to ensure it always matches the behaviour of the real system.)
Work out how to define “just enough” for your context
The next step in deciding how to approach testing for your specific context is to go through your use cases and for each one attempt to define what constitutes “just enough” for the three high-level testing objectives. This means asking yourself questions like:
- What behaviours or integration points do we need to test?
- What behaviours or integration points can we get away without testing?
- Where is a fast feedback loop critical? And exactly how fast does this need to be?
- Where can we tolerate a slower feedback loop?
- Can we cover this test case with an integration (or even E2E) test or should we also spend time writing unit tests for it?
Many of these answers will be specific to your organisational and functional requirements. But the good news with serverless applications on AWS is that there are general patterns for testing common use cases based on the AWS services being used that you can use to inform your decisions.
If you’re interested in learning more about these patterns, I cover several of them in the 4-week Serverless Testing Workshop. The workshop is a mixture of self-paced video lessons alongside weekly live group sessions where you will join me and other engineers to discuss and work through different testing scenarios.
Further reading
- The Pains of Testing Serverless Applications by Paul Swail
- Serverless, Testing and two Thinking Hats by Mike Roberts
- Test pyramid by Martin Fowler
- Test honeycomb for testing microservices by Andre Schaffer & Rickard Dybeck (Spotify Engineering)
Other articles you might enjoy:
Free Email Course
How to transition your team to a serverless-first mindset
In this 5-day email course, you’ll learn:
- Lesson 1: Why serverless is inevitable
- Lesson 2: How to identify a candidate project for your first serverless application
- Lesson 3: How to compose the building blocks that AWS provides
- Lesson 4: Common mistakes to avoid when building your first serverless application
- Lesson 5: How to break ground on your first serverless project