Routing requests away from a legacy API — A Serverless Migration Decision Journal

This is part 2 in the series Migrating a Monolithic SaaS App to Serverless — A Decision Journal.
Last time round, I made my first big decision around how to proceed with the migration. I decided to rewrite the API code from Express.js to API Gateway/Lambda before migrating the database away from MongoDB.
My first preparatory task was to create 2 AWS accounts for hosting the new resources in isolated dev/staging and production environments. I’ve completed this and documented it here.
As-is Architecture
Before I decide the next item to tackle, here’s what the current architecture looks like:
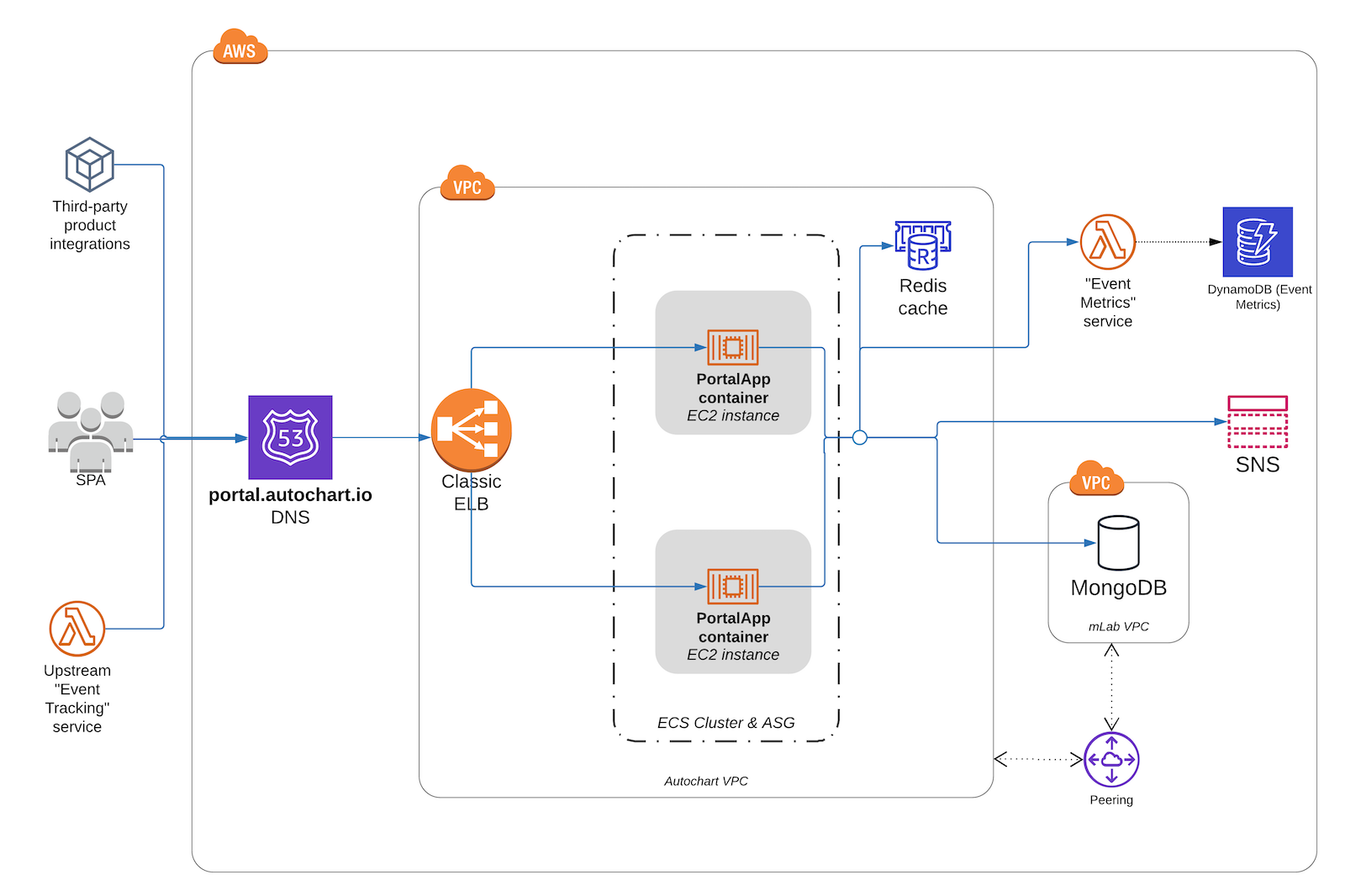
Lots of serverful resources (ELB, EC2 instances, ECS cluster, Docker containers, VPC, MongoDB, Elasticache) that I eventually want to completely supplant or obsolesce.
The PortalApp container resource is a Docker container that runs a Node.js process which hosts the entire Express.js legacy API. The vast majority of downstream calls from it are to the MongoDB database, although a few API routes call on to other services such as Redis.
Upstream from the API are:
- an AngularJS single page app that is the main user interface for end users
- third-party integrations that use the API to make synchronous data retrieval calls
- an upstream “event tracking” service. This service uses API Gateway and Kinesis to capture clickstream from customer website. A Lambda handler listens for Kinesis events and then calls on to the legacy API to save the captured event data against visitor records inside MongoDB.
The contracts of the REST API endpoints used by the SPA (1) and third party integrations (2) cannot be changed, although there is more flexibility in changing the interface to the internal API calls (3).
Starting the incremental migration
One of my constraints is that I need to migrate in small chunks. A big bang cutover is not an option. So to do this, I need to identify what these small chunks are and how to deploy each chunk to production. Put another way, there are 2 questions I now need to answer:
- What API routes should I start the migration with? To answer this, I need to identify the microservice boundaries within monolith API.
- How will I selectively intercept inbound API requests to the new serverless implementation? To answer this, I need to identify a “strangler” mechanism to use.
I’m not immediately sure which one of these makes sense to attack first. Is one dependent on the other? Let’s dig a little deeper…
Option 1: Start with identifying microservices boundaries
- ✅ Once complete, I’ll have a better picture of the overall scope and effort involved and can put together a sequenced plan.
- ✅ Doing this analysis should unearth the most risky/complex parts of the code rewrite, in particular ones that I haven’t considered or have subconsciously underestimated to date.
- ❌ This will take a while to complete as I’ll need to analyse the whole codebase to identify all upstream and downstream dependencies of each API call. Some of this code was written as long as 6 years ago, so it’s not fresh in my mind.
Option 2: Start with the request interception mechanism
- ✅ I already know that all inbound requests to the legacy API are made publicly over HTTPS to the same URL subdomain (using custom authentication & authorisation), even “internal” API calls made by jobs/microservices. So I should only need to put the intercept hook in one place.
- ✅ This mechanism will be upstream of the new code, so it seems logical to know how the new code will be invoked, and at what level of granularity it will be able to intercept requests (e.g. by URL path, verb, other request params/headers).
- ✅ I may wish to use IAM as the auth mechanism for internal API calls, so I need to see if the intercept mechanism can support this.
- ✅ This should be achievable within a few hours at most.
- ❌ In order to test this out in production, I’ll need to have identified at least 1 (low risk) route to migrate and deploy (or just add a new dummy endpoint to the API)
I’m going to start with Option 2, as I should be able to get this done pretty quickly.
Where to do the interception?
There are 2 general approaches I could take here:
- Use a component in the existing architecture with routing capabilities and configure it to forward “migrated” routes to new code and keep the rest as they are.
- Add a new resource in front of the existing architecture which does the routing.
For approach #1, the benefit here is that all existing requests (which aren’t yet being migrated) will all come in through the same front door they’ve always done. The obvious candidate here is to use the Elastic Load Balancer.
However, the current architecture uses a Classic ELB and path-based routing is only supported using Application Load Balancers. Switching this out to an Application ELB seems risky as all new requests would now be going via a new component (negating the main benefit of this approach).
The other option is to update the Express app to forward on new requests. But this seems very messy and means all requests would still be constrained by the EC2 instance capabilities. I don’t want to have to deploy a new version of the Express app every time I have a new route ready to migrate.
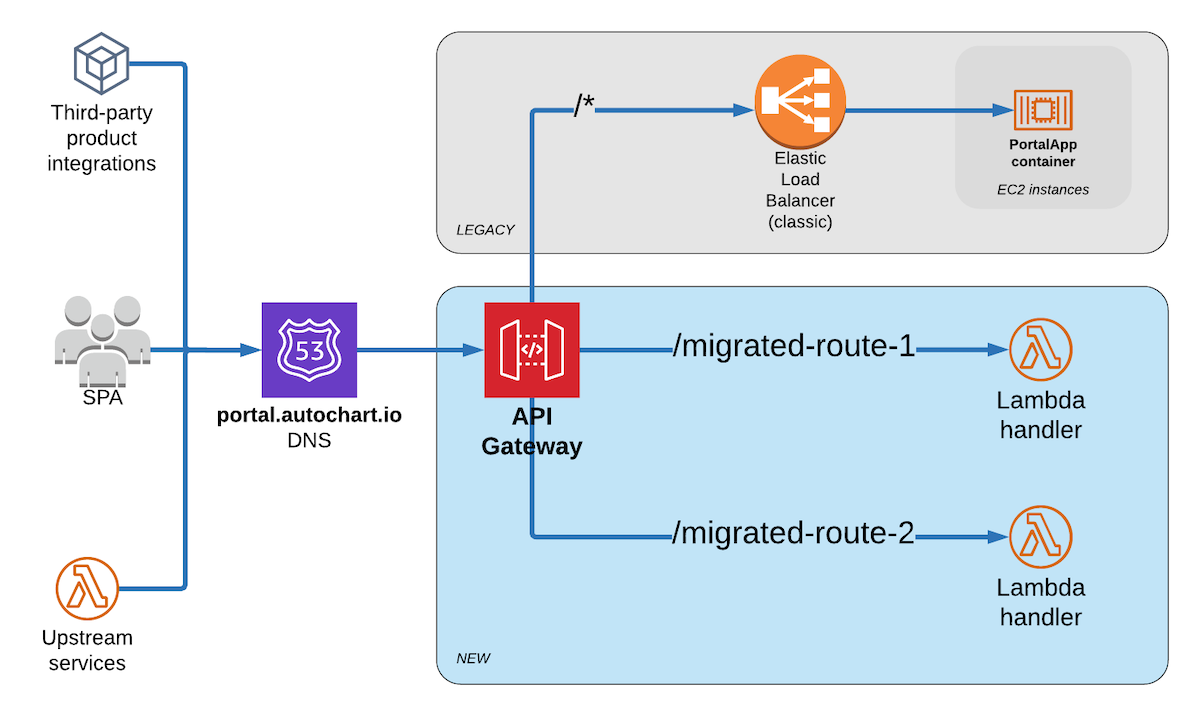
Which leaves approach #2. The obvious choice here is API Gateway as it allows path-based routing and is what I would be using anyway for the new serverless API. The downside is that it’s a slightly bigger change to the existing architecture than I’d like (since all requests will now be going through a new front door). But I think this is an acceptable risk that I can mitigate with some simple testing and is easy to rollback if something goes wrong by just pointing the DNS back at the ELB.
So here’s how the request routing will flow:
Next Steps
Now that I’ve decided to go with API Gateway as my front door router, my next step will be to deploy a gateway instance with a single test route and Lambda function handler, then update the DNS entry to point at it. I will be using the Serverless Framework to manage the routing configuration and make deployments easier.
I’ll update you on this in my next post, by which time I should have my first piece of migrated code in production. 🤞
Other articles you might enjoy:
Free Email Course
How to transition your team to a serverless-first mindset
In this 5-day email course, you’ll learn:
- Lesson 1: Why serverless is inevitable
- Lesson 2: How to identify a candidate project for your first serverless application
- Lesson 3: How to compose the building blocks that AWS provides
- Lesson 4: Common mistakes to avoid when building your first serverless application
- Lesson 5: How to break ground on your first serverless project