Setting boundaries in your serverless application

Arguably the main job of a software architect is drawing boundaries in the right places.
We love to discuss the why, when and how of splitting things up — monorepo vs multi-repos, single vs multi-table DynamoDB models, the pros and cons of Domain-Driven Design and fat vs single-purpose Lambda functions.
A case in point is this Twitter poll I ran last week about a particular hybrid style of serverless architecture that sparked a few interesting threads:
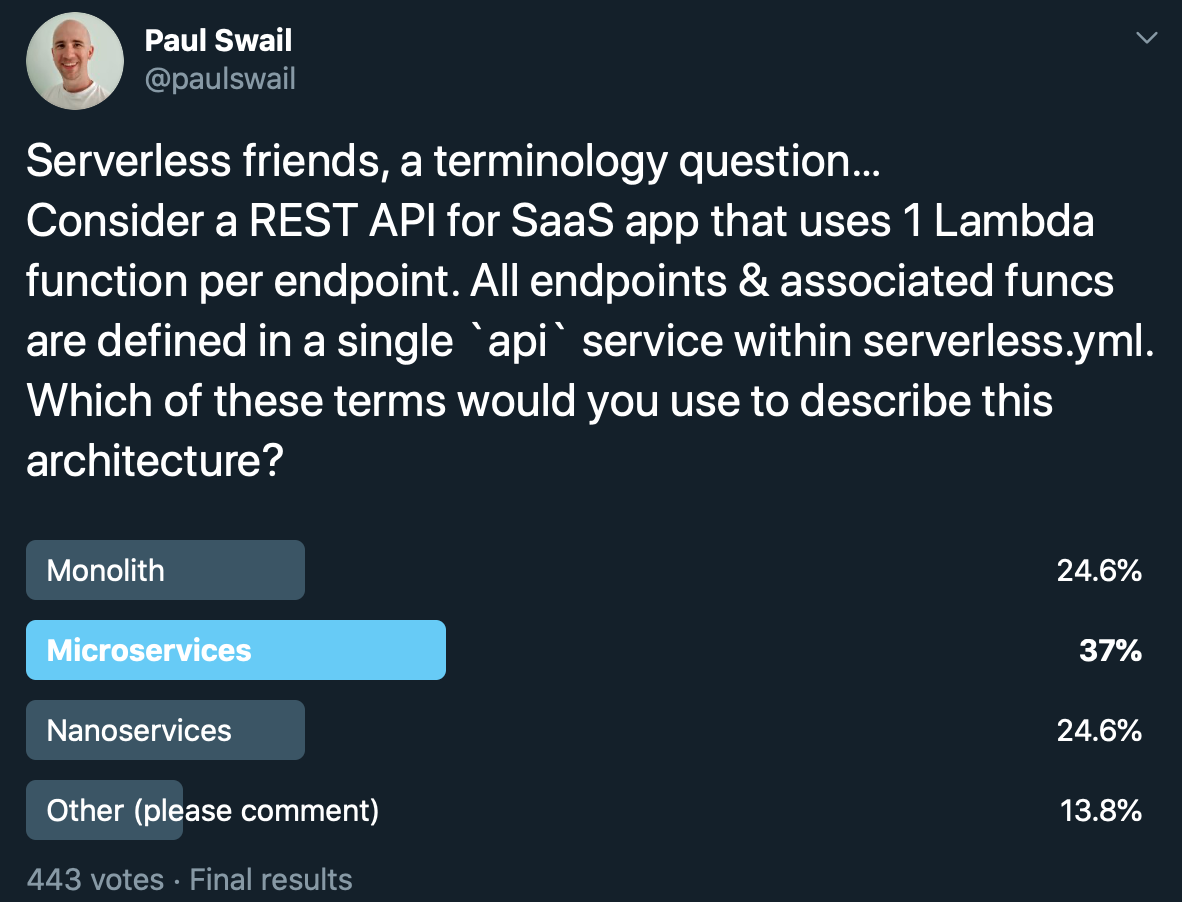
As you can see from the poll results, opinions were split. Here’s a selection of questions and observations from the replies:
- “Do all Lambda functions talk to a single shared database schema?”
- “Are there multiple bounded contexts within the system?”
- “Are there any asynchronously triggered Lambda functions?”
- “Are all Lambda functions in the same monorepo?”
- “The separation of functions allow for some fine-grained scaling and security benefits, but all business concerns are tightly coupled and can not be deployed, managed, or scaled independently.”
- “Microservices architecture deployed monolithically”
- “Monolith because an entire api should probably be split in to domain specific serverless.yaml”
- “Wouldn’t you say it’s a microservice if the single API serves a single, concise purpose?”
- “Monolith probably doesn’t fit, but is it otherwise a single “micro”-service?”
- “This is almost a hybrid of standard application deployment with microservice infrastructure.”
Of course, being the internet there were a few snarky condemnations for not following their favoured dogma in its purest form.
The terminology doesn’t really matter but understanding your context well does
While having a concise name to describe a high-level architectural pattern is nice, it’s not the most important thing. Building a system that’s valuable to its users and sustainable in the long term is.
To do so, you need a strong appreciation of the entire context in which the system will be built and operated. But there are so many complicating factors within this context that will influence any boundary-drawing decisions you make. Let’s look at several questions you’ll need to consider:
-
Organisational constraints:
- How many engineers are available to work on the project team?
- Will there be more than one engineering team working on the project?
- Could these engineers potentially be working on other projects simultaneously? And will they be the ones supporting it into production?
- How familiar is the team with general DevOps practices?
- How familiar is the team with the main AWS serverless services?
- Are application developers full-stack or are front and back-end developers primarily separate roles?
-
Project/Application constraints:
- How well defined is the problem domain and its associated user stories at the project outset?
- What is the projected growth of the application?
- What time pressures are there on project delivery?
- What in-house legacy systems do we need to integrate with?
- What third-party services do we need to integrate with?
- Are there any special low-latency requirements?
- Does sensitive user data need to be processed or stored?
There are a lot of questions I haven’t stated and many questions will lead to further questions. And so on.
No two custom software development projects are the same, so why do many folks try to fit a system into their preferred strict architectural style? Which leads me to my main point…
Cherry-picking aspects of mono, micro and nano is a valid approach
In fact, this is my standard approach when starting a new greenfield project.
Neither monoliths nor microservices (nor nanoservices) have “won” the argument for the best architecture style to build production software systems. So being a dogmatic adherent to one over the others is doing a disservice to the rest of your project team.
While you will probably have a preference for one style, you don’t need to go all-in on it, especially at the start of a project. I’m sure the architect who starts out by creating separate Git repositories and CI/CD pipelines for every individual single-purpose Lambda function is a nice guy but I cannot envision any project in which this would ever make sense.
On the other hand, you could initially identify a few bounded contexts and keep them in their own separately deployable service but still store them all in a single monorepo. Or you might start with a single CI/CD pipeline that deploys all the services together but at a later stage you can work on giving each service their own pipeline.
These are perfectly good decisions provided they’re made with the understanding of the trade-offs in your own context.
There’s that context word again…
— Paul.
Other articles you might enjoy:
Free Email Course
How to transition your team to a serverless-first mindset
In this 5-day email course, you’ll learn:
- Lesson 1: Why serverless is inevitable
- Lesson 2: How to identify a candidate project for your first serverless application
- Lesson 3: How to compose the building blocks that AWS provides
- Lesson 4: Common mistakes to avoid when building your first serverless application
- Lesson 5: How to break ground on your first serverless project