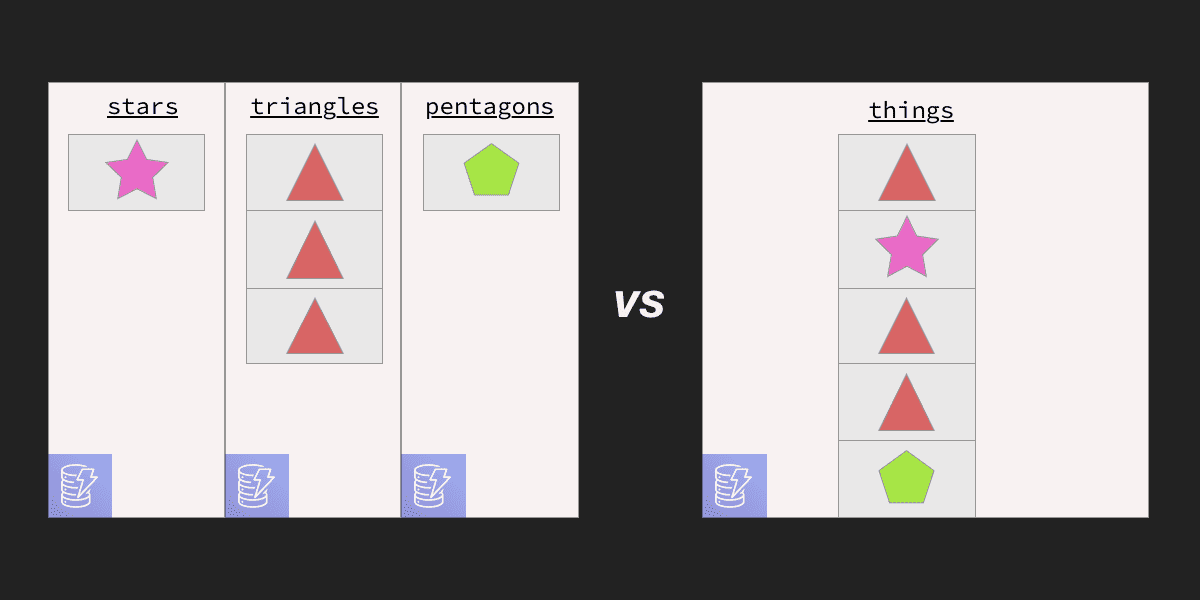
Comparing multi and single table approaches to designing a DynamoDB data model

DynamoDB is the predominant general purpose database in the AWS serverless ecosystem. Its low operational overhead, simple provisioning and configuration, streaming capability, pay-per-usage pricing and promise of near-infinite scaling make it a popular choice amongst developers building apps using Lambda and API Gateway as opposed to taking the more traditional RDBMS route.
When it comes to designing your data model in DynamoDB, there are two distinct design approaches you can take: multi-table or single-table. In this article, I will explore how both design approaches can impact the Total Cost of Ownership of your application over the lifecycle of its delivery and hopefully help you decide which approach is right for your needs.
What are the key differences between each approach?
Let’s start with an overview of what each involves:
- Multi-table — One table per each type of entity. Each item (row) maps to a single instance of that entity and attributes (columns) are consistent across every item. This is the way most people are used to thinking about data models and, in my anecdotal experience, the most common approach used.
- Single-table — One table serves the entire application or service and holds multiple types of entities within it. Each item has different attributes set on it depending on its entity type. I find this approach to be less common (at least in terms of articles and code examples on the internet) and is definitely a harder concept to grasp for most newcomers to DynamoDB. But crucially, this approach is the one that the AWS DynamoDB team espouses (somewhat without qualification) in their official docs:
You should maintain as few tables as possible in a DynamoDB application. Most well designed applications require only one table.
The primary benefits of single-table design are faster read and write performance at scale and lower cloud bill costs. At the core of its design pattern is the concept of “index overloading”. This means that a single index (both Global Secondary and Local Secondary) on your one table can be used to support several different query patterns. This enables SQL-like JOIN queries to be performed, whereby multiple related entities are fetched in a single round trip to the database. This pattern is not possible in a one entity per table model. Secondly, since indexes are multi-purpose, less indexes are needed in total. This means there are fewer indexes to update whenever a write is performed, resulting in both faster writes and a lower billing cost.
I appreciate this has been a very brief introduction to single-table design, so if you’re totally new to it and are still wondering “how can you squeeze different entities into the same database table?”, please check out the links in the resources section below.
My experience with both approaches
Up until mid-2019, I had only ever used a multi-table approach to data modelling in DynamoDB and more generally in NoSQL databases as a whole (I previously used MongoDB regularly). Since then, I’ve worked on several greenfield projects that use a single-table data model to underpin transaction-oriented apps.
In the remaining sections, I’ll walk through each phase involved in a typical project delivery as it relates to your application’s database.
Big design up front
Before any database tables are provisioned or a single line of code is written, the first step is to design your data model. The official DynamoDB docs state the following general guideline for any type of NoSQL design:
… you shouldn’t start designing your schema until you know the questions it will need to answer. Understanding the business problems and the application use cases up front is essential.
This second sentence struck me when I first read it. I work almost exclusively on agile-delivered projects where changes related to client feedback are the norm. Does this then rule out DynamoDB (and NoSQL in general) for me altogether on these projects? The short answer to this is “no” and there are strategies for managing changes (which I’ll get to later), but there’s no getting away from the fact that there is more Big Design Up Front with DynamoDB versus using a SQL database. But the “serverlessness” benefits of DynamoDB over an RDBMS that I described in my opening paragraph above outweigh the impact of this upfront design effort IMHO.
In terms of tools, I use a spreadsheet to define my design and have seen many DynamoDB experts doing the same. AWS have recently released a new tool DynamoDB NoSQL Workbench that as of this writing is in early preview, but will hopefully provide a bit more structure to the data modelling design process.
The design process
So what is the process for creating your data model? Jeremy Daly has a great list of 20 steps for designing a DynamoDB model using a single-table approach that I recommend you check out as it’s a quick read. Steps 11–14 in particular should give you a flavour of the level of rigour required:

The main schema difference you will see between single and multi-table models is that single-table will have generically named attributes that are used to form the table’s partition and sort key. This is required because different entity types will likely have differently named primary key fields. A common convention is to use attributes named pk and sk that map to the table’s partition and sort keys respectively. Similar generically named attributes may be used for composite keys that make up GSIs or LSIs.
Provisioning and configuration management
So now we have our data models designed, it’s now time to provision our tables. This is probably the easiest step of the whole development process.
DynamoDB has good CloudFormation support which makes Infrastructure-as-Code a breeze. With a few lines of YAML and a CLI deploy command you can quickly provision your DynamoDB tables and indexes along with associated IAM access control privileges in less than a minute. I use the Serverless Framework which allows raw CloudFormation to be embedded in the resources section.
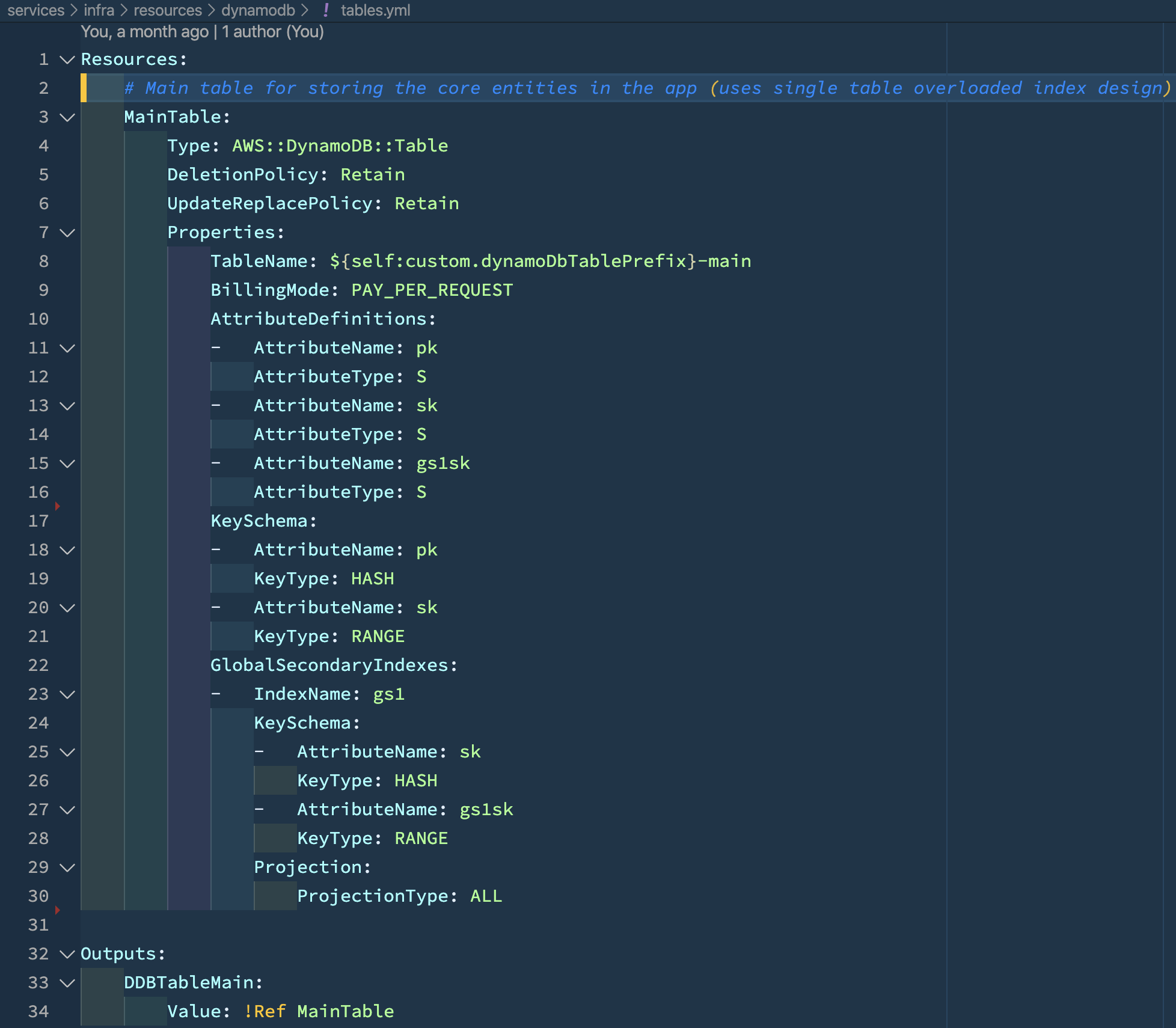
This area is one where the single-table approach wins out in terms of less configuration to manage and faster provisioning — I only need to define one table and pass its name into my Lambda functions as an environment variable. In the multi-table approach, I have config and environment variables for each individual table. A minor benefit in the entire scheme of things, but still nice.
Implementing data access in the codebase
Your database is now deployed and it’s time to start talking to it from your application. Chances are you will have domain entity objects that you pass around in your code (e.g. in API request/response payloads or SNS / SQS messages). If you need to persist these entities to your database, you can use one of the higher-level AWS DynamoDB SDKs (such as the DocumentClient for Node.js) to do so. But there are a few key differences between multi and single table designs here…
Writing objects to the database
In a multi-table design, you can often just write your in-memory domain object directly to the database as-is without any mapping. Fields on your object will become attributes in your DynamoDB item. Occasionally you may need to create a concatenated composite field that’s used in an index in order to support a particular filtering or sorting requirement.
In a single-table design however, there will always be some mapping you need to do at write-time. Specifically, you will need to add 2 new fields pk and sk to your domain object before persisting it to DynamoDB. If you’re using other generic composite index fields, then you’ll also need to do the same for each of them. The values of these fields need to match the formats defined in your data model spreadsheet. I find that I usually need to concatenate a static prefix (that uniquely identifies the entity type and prevents collisions) to one or more fields from my domain object that I need to filter or sort on.
Partial item updates are more complex again. Given that in single-table design there is data duplication within each item, if you are using the DynamoDB UpdateItem API to update a single field, you need to check whether that field is also used within a composite indexed field, and if so, also update the value of the composite field. I’ve forgot about this several times and it can be quite difficult to remedy.
Reading objects from the database
When you fetch items back from DynamoDB (via GetItem or Query API calls), you will almost always want to strip off the composite indexed fields before, say, returning the entity to the client who is calling your API. Unfortunately, the DynamoDB API calls do not allow you to blocklist attributes that you don’t want to return. So instead, you either have to allowlist all the other fields that you do wish to return (by using a ProjectionExpression) or you do the blocklisting in your application code after the query returns. I usually take the latter option as it’s less code to maintain, despite being slightly less performant (as more data is being returned than what I need).
Strategies for controlling code complexity in a single-table design
For both reads and writes, you will find yourself doing a lot of string concatenations using the same prefixes and separator characters. This can be quite error prone. For this reason, I recommend you keep all data-access code for each entity type within a single module/file so you can quickly reference how an entity was created when you are writing a function to query or update it.
In serverless apps, I usually structure my code such that a Lambda handler would handoff to a model / service module which would then be responsible for doing data access as well as talking to any other downstream services (SNS, etc). If your data access code becomes sufficiently complex (which it easily can once composite fields are introduced), there is a case for using the repository pattern whereby you create modules whose sole responsibility is to perform DynamoDB operations for a particular entity type.
Another recommendation for increasing the maintainability of your data access code is to keep your data model design spreadsheet up-to-date and have it reviewed alongside the code as part of your pull request process. I’ve found it helpful to have an “Implementation Status” flag column or colour code in my design spreadsheet as part of each query pattern showing whether it’s been implemented yet.
Schema migrations
This is the scenario the official AWS docs warned you about. Those business use cases that you fully understood at the project outset have changed! You need to make changes to your existing access patterns — maybe change a sort order or filter on a different field. Broadly, the solution to this will involve either or both of the following:
- Creating a new GSI/LSI index pointing at the new fields (optionally also dropping an existing index that’s no longer needed)
- Writing a migration script that scans a table and performs per-item updates, such as amending the value of a composite indexed field.
Once the new indexes/composite indexed fields are in place, then the application code updates can be deployed. You may want to then run a cleanup script to remove the old composite fields / indexes.
Such a migration script can be difficult to manage, especially in a single-table design which is highly dependent on composite indexed fields. Full table scan operations can take a long time to complete. So while it’s running, your database will be in an inconsistent state with some items patched and some not. You may need to write your script such that it can operate on smaller batches/partitions and ensure that it’s idempotent (e.g. by storing state somewhere to show what migrations have been applied or what items were already patched) . Also, I could not find any well-known tools that currently help with this in the same way as the likes of Rails ActiveRecord Migrations works with SQL databases.
I haven’t yet hit this issue in a post go-live production environment so I haven’t explored in-depth what solutions are currently available to this. If you have a good strategy for managing schema migrations, then please let me know in the comments.
Integrating with other data stores
Another concern that affects single-table designs is that some managed services that have built-in integrations for exporting data out of DynamoDB (for analytics) expect each table to map to a single domain entity. Exporting a single table that contains entities of varying shapes just won’t work without some custom-built intermediate step to perform a transform. An example of this is the DynamoDB to Redshift integration . This might be something you need to consider when choosing your design approach.
When should you use either approach?
We’ve covered the impact of multi-table vs single-table design approach on each stage of the delivery lifecycle from design right through to post-go-live change management. The big question that now remains is when should you choose one approach over the other?
The overly simplistic AWS official line of “Most well designed applications require only one table” doesn’t do the nuance of this decision justice IMHO. It implies that if you don’t use the single table approach that your application is not well designed. But their definition of “well designed” only considers performance, scaling and billing costs and neglects the other considerations that go into the Total Cost of Ownership of an application.
So for me, it comes down to answering this question — what do you want to optimise for:
- time to market and flexibility of requirements; or:
- performance, scalability and efficient billing cost?
One of the core tenets of the serverless movement is that it allows developers to focus more on the business problem at hand and much less on the technical and operational concerns that they’ve had to spend time on in the past working in server-based architectures. Another core tenet is near unlimited scalability. Often both of these are in tandem, but in this debate they are pulling against each other.
The multi-table approach is an easier on-ramp for developers coming from an RDBMS background (which is the majority of developers). Adding the single table design approach on top of that cranks up the steepness of the learning curve. Add in the rigidity enforced by designing overloaded indexes and the overhead if any migrations need to be performed, then I think it’s fair to say that for most teams, they would ship an app faster using the multi-table approach
With a multi-table model, I would argue that your team will be less dependent on the presence of a resident “DynamoDB modelling expert” in order to implement or approve any changes to the application’s data access. I’m sure most of you have experienced part of an application architecture or codebase that you’re afraid to touch because you don’t really understand it and seems a bit like magic.
All that said, once you do get the hang of the single-table approach and learn new strategies for creating composite indexes to support new query patterns, it’s undoubtedly very powerful. Your code only needs to make one fast database round-trip to fetch a batch of related entities. And you get that warm fuzzy feeling of confidence that your app performance and billing costs are as optimised as they can be. (But remember the cost of your engineer’s time usually trumps the cost of your cloud service bill).
Learn more
If you’d like to learn more about data modelling in DynamoDB, here’s a list of resources that have helped me:
- AWS re:Invent 2018: Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB (DAT401) - YouTube
- From relational DB to single DynamoDB table: a step-by-step exploration — Forrest Brazeal
- Best Practices for Managing Many-to-Many Relationships - Amazon DynamoDB
- Build with DynamoDB - S1 E3 – NoSQL Data Modeling with Amazon DynamoDB - YouTube
- Reddit discussion: how many people are doing true “single table” dynamo DB (vs multiple tables)
- How to switch from RDBMS to DynamoDB in 20 easy steps — Jeremy Daly
- Using (and Ignoring) DynamoDB Best Practices with Serverless — Alex DeBrie
- DynamoDB Book— Model DynamoDB the Right Way — AlexDeBrie
Thanks to Darren Gibney for providing review on this post.
Other articles you might enjoy:
Free Email Course
How to transition your team to a serverless-first mindset
In this 5-day email course, you’ll learn:
- Lesson 1: Why serverless is inevitable
- Lesson 2: How to identify a candidate project for your first serverless application
- Lesson 3: How to compose the building blocks that AWS provides
- Lesson 4: Common mistakes to avoid when building your first serverless application
- Lesson 5: How to break ground on your first serverless project